

FILTERXML là một hàm được sử dụng trong Excel để lấy thông tin từ những đoạn XML. Hiện hàm này khả dụng trong các phiên bản Excel 2013, 2016, 2019, 2021 và Excel 365 cho Windows (không khả dụng với Excel trên Web và Excel cho Mac). Mục đích đầu tiên của hàm là kết hợp với 2 hàm khác bao gồm ENCODEURL và WEBSERVICE để lấy dữ liệu dưới dạng xml về và xử lý chúng. Tuy vậy, có rất nhiều cách để ứng dụng Xpath trong FILTERXML để xử lý các bài toán tách chuỗi. Dưới đây sẽ là 7 ứng dụng tách chuỗi với hàm FILTERXML trong Excel
Hàm FILTERXML được viết như sau:
=FILTERXML(xml,xpath)Trong đó, xml là đoạn định dạng xml của chúng ta, còn xpath là chuỗi ở dạng standard xpath. Phiên bản xpath được sử dụng là 1.0.
Dưới đây là một ví dụ về đoạn xml:

Những thành phần được ghi trong cặp dấu <> gọi là các element. Ngoài ra chúng ta còn có 1 số đối tượng khác như attributes, namespaces nhưng trong phạm vi bài viết này ta sẽ không đi quá sâu. Để tìm hiểu thêm, Học Excel Online gợi ý bạn đọc 2 nội dung về xml và xpath trên w3school để có cái nhìn cơ bản:
XML:
Xpath:
Quay trở lại với bài viết, ta có thể biến một chuỗi bất kỳ thành định dạng xml bằng hàm SUBSTITUTE đơn giản. Trong bài viết này, ta sẽ có ví dụ là 1 chuỗi như sau:
Hieu, Hieu, An, Nam, An, 100, 1234, Thuc, Tuan Anh, 567, An, Tuan, Long
Để thuận tiện sử dụng FILTERXML, chuỗi được biến đổi với công thức:
="<a><b>"&SUBSTITUTE(chuỗi,", ","</b><b>")&"</b></a>"Kết quả:
<a><b>Hieu</b><b>Hieu</b><b>An</b><b>Nam</b><b>An</b><b>100</b><b>1234</b><b>Thuc</b><b>Tuan Anh</b><b>567</b><b>An</b><b>Tuan</b><b>Long</b></a>
Từ đây, có thể nghĩ đến những ứng dụng vô cùng mạnh mẽ với FILTERXML. Trong những công thức dưới, mặc định “xml” là chuỗi đã được biến đổi bên trên
1. Tách chuỗi với hàm FILTERXML
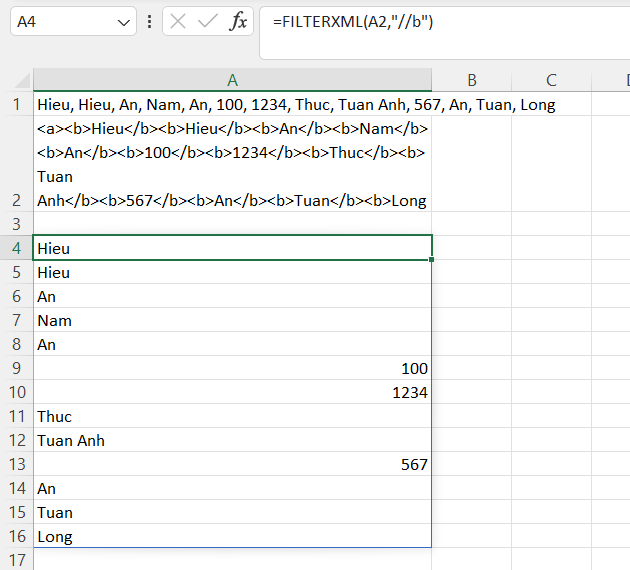
=FILTERXML(xml,"//b")FILTERXML có khả năng tách chuỗi và trả về kết quả theo chiều dọc. Nếu phiên bản bạn đang sử dụng không phải là Office 365, cần chọn vùng trả kết quả (theo chiều dọc) trước, nhập công thức và ấn Ctrl + Shift + Enter. Nếu bạn chưa hiểu, vui lòng đọc bài viết về cách viết công thức mảng trước:
Còn nếu bạn đang sử dụng Office 365, chỉ cần ấn Enter thì tất cả các phần tử được tách sẽ hiển thị thành một cột. Và bạn có biết Xpath sẽ tự động Trim những khoảng trắng ở đầu không?
Ứng dụng nâng cao: Gộp cột với TEXTJOIN
Trong Office 2019 chúng ta đã có TEXTJOIN, tuy nhiên chưa có hàm chồng cột mới là VSTACK. Vậy nên nếu bạn có 1 bảng nhiều cột/mảng 2 chiều, các bạn có thể gộp các giá trị lại với TEXTJOIN, rồi tách bằng FILTERXML để được hiệu ứng gộp cột. Còn nếu muốn gộp thành 1 hàng? Thêm 1 hàm TRANSPOSE là câu trả lời cho bạn.

2. Lấy một phần tử xác định trong chuỗi
=FILTERXML(xml,"//b[nhập số vào đây]")Ta có thể xác định phần tử cần lấy bằng cách nhập vị trí của phần tử vào trong dấu ngoặc vuông. Chẳng hạn, để lấy phần tử thứ 3, ta sẽ đặt là //b[3] và khi đó hàm sẽ trả về duy nhất 1 phần tử.
Ứng dụng nâng cao: Kết hợp với MATCH để lọc ra những thông tin cần lấy.
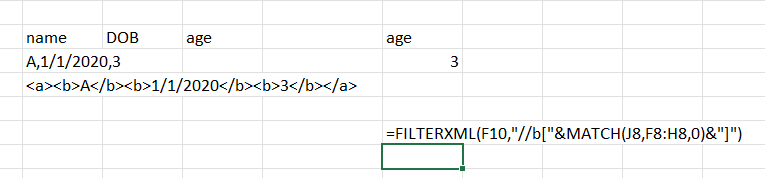
Giả sử chúng ta có 1 chuỗi csv theo dạng “A, 1/1/2020, 3” và 3 tiêu đề cột tương ứng là “Tên, DOB, Tuổi”. Để lấy tuổi ta sẽ lồng hàm MATCH vào trong FILTERXML như ảnh:
3. Lấy giá trị theo khoảng vị trí
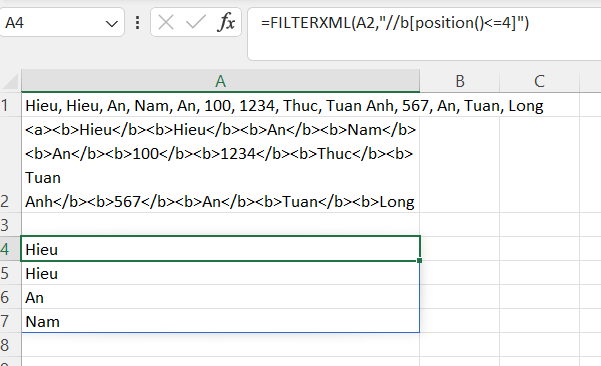
=FILTERXML(xml,"//b[position()<=nhập số vào đây]")Ngoài cách viết ngắn gọn //b[nhập số] như trên, ta có thể viết khái quát bằng hàm position(). Chẳng hạn, nếu muốn lấy 4 giá trị đầu, ta viết //b[position()<=4]. Khi đó, chuỗi xml sẽ trả về kết quả như hình:
4. Lấy những ô chứa kí tự được xác định
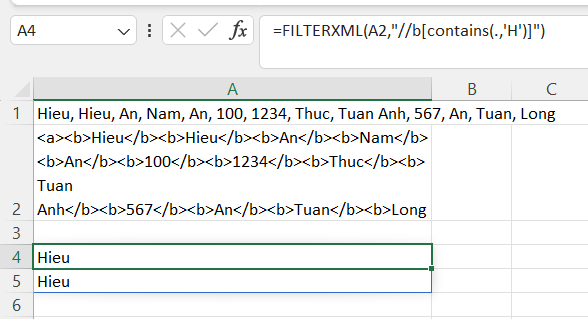
=FILTERXML(xml,"//b[contains(.,'nhập kí tự vào đây, lưu ý đây là dấu nháy đơn')]")Ta có thể sử dụng hàm contains() để xác định xem những phần tử đó sẽ chứa kí tự nào. Chẳng hạn, để lấy những phần tử có chứa chữ “H” (lưu ý, khi đưa kí tự vào contains, ta kẹp vào trong dấu nháy đơn chứ không phải nháy kép:
5. Map giá trị trong Xpath
=FILTERXML(xml,"//b[translate(.,'bộ kí tự cần map','bộ kí tự map')=.]")Trong Xpath, ta có hàm translate() có tác dụng map các kí tự thay cho nhau. Để hiểu hơn về hàm này, các bạn đọc thêm tại link sau: https://developer.mozilla.org/en-US/docs/Web/XPath/Functions/translate.
translate('abcabc','ab','xy') => xycxycỨng dụng của công thức trên là ta có thể so sánh các giá trị sau khi map với giá trị ban đầu, từ đó lọc ra các phần tử cần lấy. Ví dụ dưới đây sẽ lấy tất cả các giá trị không chứa số:
=FILTERXML(xml,”//b[translate(.,’1234567890′,”)=.]”)
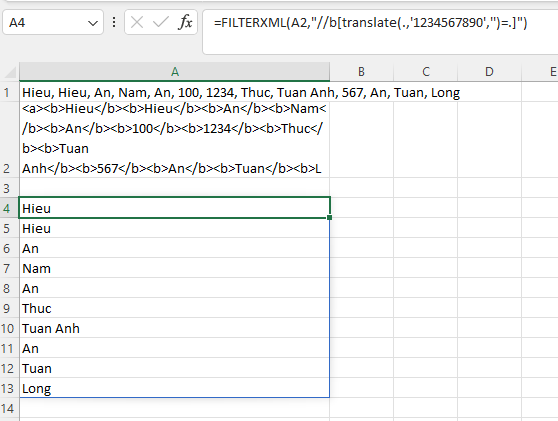
Lưu ý: Ở đây sẽ lấy ra các giá trị không chứa số, chứ không phải các giá trị không phải là số. Bởi vậy, nếu bạn có 1 phần tử kiểu “Th12uc”, phần tử này cũng sẽ bị loại trừ bởi có chứa số bên trong.
6. Lấy những phần tử là số
=FILTERXML(xml,"//b[number()=.]")Với sự kết hợp cùng hàm number(), ta có thể lấy ra các giá trị số trong chuỗi xml như ảnh:
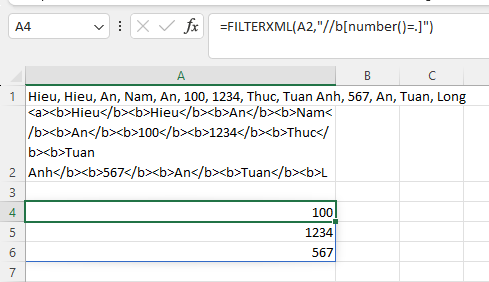
Một cách viết khác cũng cho kết quả tương tự:
=FILTERXML(xml,"//b[boolean(number())]")7. Tách các giá trị không trùng lặp
=FILTERXML(xml,"//b[not(. = following-sibling::*)]")Sử dụng Xpath axes following-sibling, ta có thể lấy ra được các phần tử “distinct”, có nghĩa là mỗi phần tử sẽ không lặp lại trong mảng kết quả trả về. Với các máy chưa có hàm UNIQUE, đây là một sự thay thế rất hữu dụng.
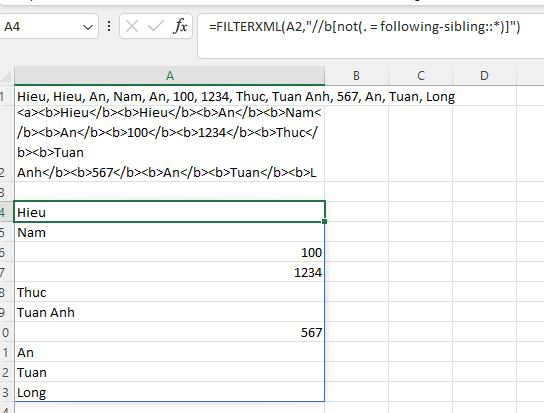
Qua bài viết ta có thể thấy FILTERXML là một hàm vô cùng hữu dụng, tuy nhiên từ trước tới nay có một số nguyên nhân khiến ta chưa ứng dụng được vào trong nhiều những tình huống thực tế như hàm chưa được phổ biến rộng ở nhiều phiên bản, cũng như Xpath không dễ hiểu với người dùng phổ thông…
Các bạn có thể đọc thêm những tính năng khác của hàm ở đây:
- Dùng hàm FILTERXML để tách và xử lý dữ liệu:
- Lấy tỷ giá ngoại tệ của Vietcombank vào Excel: